Wat is webschrapen? Hoe gegevens van websites te verzamelen
Advertentie
Webschrapers verzamelen automatisch informatie en gegevens die meestal alleen toegankelijk zijn door een website in een browser te bezoeken. Door dit autonoom te doen, openen web-scraping-scripts een wereld van mogelijkheden in datamining, data-analyse, statistische analyse en nog veel meer.
Waarom webschrapen nuttig is
We leven in een tijd waarin informatie gemakkelijker beschikbaar is dan op enig ander tijdstip. De bestaande infrastructuur die wordt gebruikt om deze woorden te leveren die u nu leest, is een kanaal voor meer kennis, mening en nieuws dan ooit toegankelijk was voor mensen in de geschiedenis van mensen.
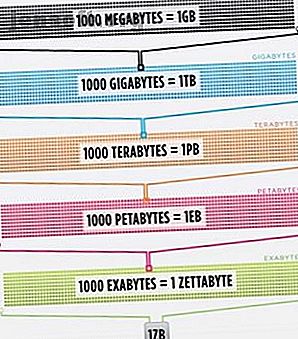
Zoveel zelfs, dat het brein van de slimste persoon, verbeterd tot 100% efficiëntie (daar zou iemand een film over moeten maken), nog steeds niet in staat is om 1 / 1000ste van de gegevens op internet alleen in de Verenigde Staten te bewaren .
Cisco schatte in 2016 dat het verkeer op het internet één zettabyte overschreed, dat is 1.000.000.000.000.000.000.000 bytes, of één sextillion bytes (ga je gang, giechelen op zes miljoen). Eén zettabyte is ongeveer vierduizend jaar streaming van Netflix. Dat zou hetzelfde zijn als als u, onverschrokken lezer, The Office van begin tot eind zou streamen zonder 500.000 keer te stoppen.

Al deze gegevens en informatie zijn zeer intimiderend. Niet alles klopt. Niet veel ervan is relevant voor het dagelijks leven, maar steeds meer apparaten leveren deze informatie van servers over de hele wereld recht in onze ogen en in onze hersenen.
Omdat onze ogen en hersenen niet echt met al deze informatie kunnen omgaan, is webscraping naar voren gekomen als een nuttige methode om gegevens programmatisch van internet te verzamelen. Webschrapen is de abstracte term om gegevens te extraheren van websites om deze lokaal op te slaan.
Denk aan een soort gegevens en u kunt deze waarschijnlijk verzamelen door over het web te schrapen. Onroerend goed lijsten, sportgegevens, e-mailadressen van bedrijven in uw omgeving, en zelfs de teksten van uw favoriete artiest kunnen allemaal worden gezocht en opgeslagen door een klein script te schrijven.
Hoe krijgt een browser webgegevens?
Om webschrapers te begrijpen, moeten we eerst begrijpen hoe het web werkt. Om naar deze website te gaan, typt u 'makeuseof.com' in uw webbrowser of klikt u op een link van een andere webpagina (laat ons weten waar, we willen het serieus weten). Hoe dan ook, de volgende stappen zijn hetzelfde.
Eerst neemt uw browser de URL die u hebt ingevoerd of waarop u hebt geklikt (Pro-tip: beweeg over de link om de URL onderaan uw browser te zien voordat u erop klikt om te voorkomen dat u wordt gepunkt) en een 'verzoek' om te verzenden naar een server. De server zal het verzoek dan verwerken en een reactie terugsturen.
Het antwoord van de server bevat de HTML, JavaScript, CSS, JSON en andere gegevens die nodig zijn om uw webbrowser een webpagina te laten vormen voor uw kijkplezier.
Webelementen inspecteren
Moderne browsers geven ons enkele details over dit proces. In Google Chrome op Windows kunt u op Ctrl + Shift + I drukken of met de rechtermuisknop klikken en Inspecteren selecteren. Het venster toont dan een scherm dat er als volgt uitziet.

Boven aan het venster wordt een lijst met tabbladen weergegeven. Op dit moment is het tabblad Netwerk interessant. Dit geeft details over het HTTP-verkeer zoals hieronder weergegeven.

Rechtsonder zien we informatie over het HTTP-verzoek. De URL is wat we verwachten en de "methode" is een HTTP "GET" -verzoek. De statuscode van het antwoord wordt weergegeven als 200, wat betekent dat de server het verzoek als geldig heeft beschouwd.
Onder de statuscode bevindt zich het externe adres, het openbare IP-adres van de makeuseof.com-server. De client krijgt dit adres via het DNS-protocol Waarom het veranderen van DNS-instellingen uw internetsnelheid verhoogt Waarom het veranderen van DNS-instellingen uw internetsnelheid verhoogt Het veranderen van uw DNS-instellingen is een van die kleine aanpassingen die grote opbrengsten kunnen opleveren op dagelijkse internetsnelheden. Lees verder .
Het volgende gedeelte bevat details over het antwoord. De antwoordkop bevat niet alleen de statuscode, maar ook het type gegevens of inhoud dat het antwoord bevat. In dit geval kijken we naar "text / html" met een standaardcodering. Dit vertelt ons dat het antwoord letterlijk de HTML-code is om de website weer te geven.

Andere soorten antwoorden
Bovendien kunnen servers gegevensobjecten retourneren als reactie op een GET-verzoek, in plaats van alleen HTML voor de webpagina die moet worden weergegeven. De Application Programming Interface (of API) van een website Wat zijn API's en hoe veranderen open API's het internet Wat zijn API's en hoe veranderen open API's het internet Heb je je ooit afgevraagd hoe programma's op je computer en de websites die je bezoekt "praten" naar elkaar? Meer informatie maakt meestal gebruik van dit type uitwisseling.
Op het tabblad Netwerk, zoals hierboven weergegeven, kunt u zien of dit type uitwisseling bestaat. Bij het onderzoeken van het CrossFit Open Leaderboard wordt het verzoek getoond om de tabel met gegevens te vullen.

Door naar het antwoord te klikken, worden de JSON-gegevens weergegeven in plaats van de HTML-code voor het weergeven van de website. Gegevens in JSON is een reeks labels en waarden, in een gelaagde, overzichtelijke lijst.

Het handmatig ontleden van HTML-code of het doorlopen van duizenden sleutel / waarde-paren van JSON lijkt veel op het lezen van de Matrix. Op het eerste gezicht lijkt het op brabbeltaal. Er is mogelijk te veel informatie om deze handmatig te decoderen.
Web Scrapers to the Rescue!
Voordat je naar de blauwe pil vraagt om hier weg te komen, moet je weten dat we HTML-code niet handmatig hoeven te decoderen! Onwetendheid is geen gelukzaligheid en deze biefstuk is heerlijk.
Een webschraper kan deze moeilijke taken voor u uitvoeren. De Scrapestack-API maakt het gemakkelijk om websites naar gegevens te schrapen. De Scrapestack-API maakt het gemakkelijk om websites voor gegevens te schrapen Op zoek naar een krachtige en betaalbare webschraper? De scrapestack-API is gratis te starten en biedt veel handige tools. Lees verder . Scraping frameworks zijn beschikbaar in Python, JavaScript, Node en andere talen. Een van de gemakkelijkste manieren om te beginnen met schrapen is door Python en Beautiful Soup te gebruiken.
Een website schrapen met Python
Aan de slag kost slechts een paar regels code, zolang Python en BeautifulSoup zijn geïnstalleerd. Hier is een klein script om de bron van een website te krijgen en BeautifulSoup deze te laten evalueren.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Heel eenvoudig, we doen een GET-aanvraag voor een URL en plaatsen het antwoord vervolgens in een object. Bij het afdrukken van het object wordt de HTML-broncode van de URL weergegeven. Het proces is alsof we handmatig naar de website zijn gegaan en op Bron weergeven hebben geklikt.
Dit is met name een website die elke dag trainingen in CrossFit-stijl plaatst, maar slechts één per dag. We kunnen onze schraper bouwen om de training elke dag te krijgen en deze vervolgens toevoegen aan een aggregatielijst met trainingen. In wezen kunnen we een op tekst gebaseerde historische database met trainingen maken die we gemakkelijk kunnen doorzoeken.
De magie van BeaufiulSoup is de mogelijkheid om door alle HTML-code te zoeken met de ingebouwde functie findAll (). In dit specifieke geval gebruikt de website verschillende tags voor "sqs-block-content". Daarom moet het script al die tags doorlopen en de voor ons interessante vinden.
Bovendien zijn er een aantal
tags in de sectie. Het script kan alle tekst van elk van deze tags toevoegen aan een lokale variabele. Voeg hiervoor een eenvoudige lus toe aan het script:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Voila! Een webschraper is geboren.
Opschalen Schrapen
Er zijn twee paden om vooruit te komen.
Een manier om webschrapen te verkennen, is met behulp van reeds gebouwde tools. Web Scraper (geweldige naam!) Heeft 200.000 gebruikers en is eenvoudig te gebruiken. Met Parse Hub kunnen gebruikers ook geschraapte gegevens exporteren naar Excel en Google Spreadsheets.
Bovendien biedt Web Scraper een Chrome-plug-in die helpt visualiseren hoe een website is gebouwd. Het beste van alles, te oordelen naar naam, is OctoParse, een krachtige schraper met een intuïtieve interface.
Eindelijk, nu je de achtergrond van webschrapen kent, je eigen kleine webschraper opvoeden om te kunnen crawlen en uitvoeren Hoe maak je een eenvoudige webcrawler om informatie van een website te halen Hoe bouw je een eenvoudige webcrawler om informatie van een te trekken Website Heeft u ooit informatie van een website willen vastleggen? U kunt een crawler schrijven om door de website te navigeren en precies datgene te extraheren dat u nodig hebt. Lees meer op zichzelf is een leuke onderneming.
Ontdek meer over: Python, Web Scraping.

